Ongoing projects
1) UAV imagery for intelligent transportation systems
This research explores the use of artificial intelligence (AI) and augmented reality (AR) technologies for efficient guidance of unmanned aerial vehicles (UAV) in various contexts of intelligent transportation systems such as delivery, infrastructure inspection and surveillance. The project has two major thrusts:
a) Concrete defect detection and bridge inspection

Concrete infrastructures, such as bridges, overpasses and roads are a foundation part for constructing urban environments, and should be maintained in a systematic manner in order to ensure their long-term quality.
This research aims at developping advanced deep learning models for efficient defect classfication, detection and segmentation on bridges, and related infrasctructures. These models integrate several features such as attention and multi-task learning for better efficiency, and are trained using several learning paradigms such as supervised, semi-supervised and unsupervised learning. An emphasis is also put on how to build lightweight models and couple them with augmented reality to be deployed in real-time inspections systems using drone imagery.
b) Safe landing zones detection for drone navigation.

As Unmanned Aerial Vehicles (UAV) are increasingly used in civilian applications, identifying safe landing zones (SLZ) in urban areas and natural scenes is one of the several challenges to overcome for automating and ensuring the safety of UAV navigation. Using passive vision sensors to achieve this objective is a very promising avenue thanks to their low cost and the potential they provide for performing simultaneous terrain analysis and 3D reconstruction. The purpose of this project is to leverage deep learning for semantic segmentation of drone imagery, whereby thematic classes of the terrain are mapped into safety grades for UAV landing. Our models can be used to identify safe landing zones in emergency situations, as well as UAV trajectory planning.
c) Smart Eyes in the Sky: AI for Risk Detection and Disaster Response

This research axis focuses on developing advanced technologies that leverage computer vision and machine learning to analyze aerial images and videos of disaster zones captured by drones. The goal is to assess risks and extract critical insights to support more informed and timely decision-making. These AI-driven solutions can play a pivotal role in disaster prevention and monitoring by delivering high-resolution, real-time data for evaluating vulnerable areas.
Prior to a disaster, such technologies enable proactive measures through hazard mapping, infrastructure evaluation, and the identification of environmental threats. In the event of a disaster, and in its aftermath, aerial imagery facilitates rapid damage assessment, locates affected or inaccessible zones, and enhances the coordination of emergency response efforts.
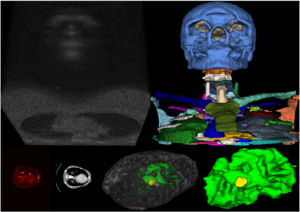
2) Medical image segmentation and classification
Medical image classification and segmentation are important for computer-aided diagnosis, treatment, and disease monitoring. Segmentation divides images into regions representing different structures or pathologies, while classification assigns labels to images or regions, like identifying pneumonia in X-rays. At the LARIVIA lab, extensive research using deep learning aims to enhance medical diagnosis accuracy, personalize treatments, and improve patient outcomes, pushing the limits of AI in healthcare.
3) Mutimedia document analysis for cybersecurity

This project focuses on developing advanced machine learning approaches for representing, analyzing and interpreting multimedia documents for cybersecurity. Applications of these approaches are mainly in spam and deepfake detection, which can involve image, video, text, and potentially audio data.
One of the leading approaches is to use cutting-edge deep learning techniques such as Large Language Models (LLMs) combined with various learning paradigms such as unsupervised, self-supervised, adversarial and metric learning to leverage various types of data and domain knowledge.
Past projects
1) Semantic image/video segmentation
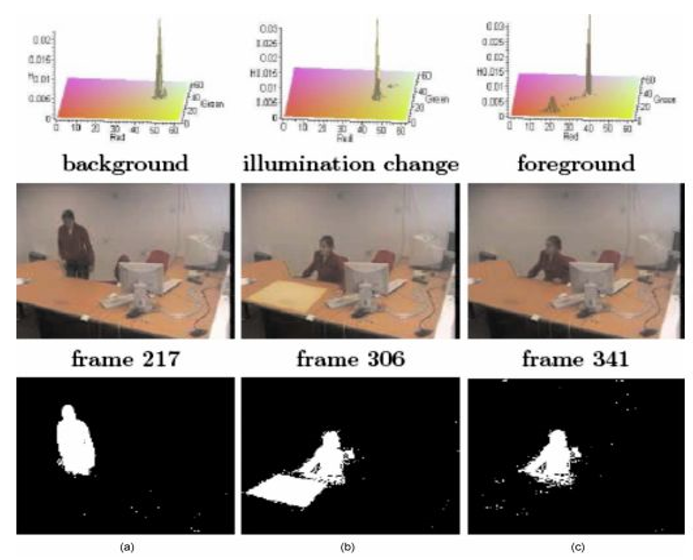
Image and video object segmentation are important problems for visual image and video understanding. This project aimed at developed robust statistical approaches based on heavy-tailed distributions for color and texture representation and segmentation.
These statistical models enhanced the resilience of segmentation to outlying data such as noise and spurious foreground and background artefacts, which enhanced the accuracy of object segmentation. Several applications have also been developped, such as image and video foreground segmentation, and object tracking.
2) Image/video activity recognition
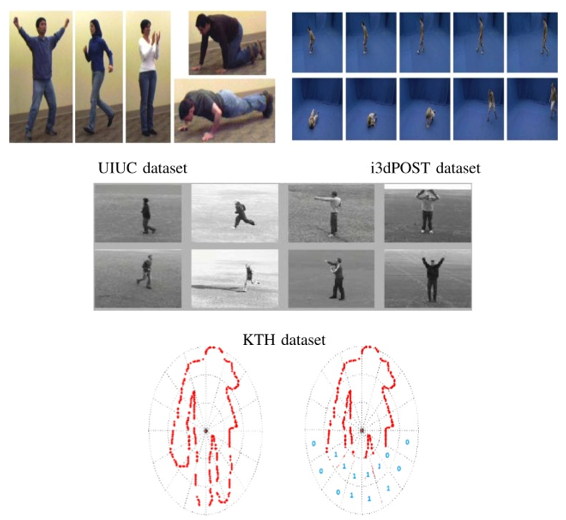
The LARIVIA laboratory previously proposed advanced statistical models based on multinomial kernel logistic regression for activity recognition in images and videos. This innovative approach significantly advanced the field of computer vision and machine learning, enabling more accurate and nuanced understanding of complex activities depicted in visual media.
By integrating multinomial logistic regression with kernel methods, these models enhanced the ability to interpret and classify diverse activities invilving inter-person interactions, a crucial step forward for applications requiring detailed visual analysis and recognition.
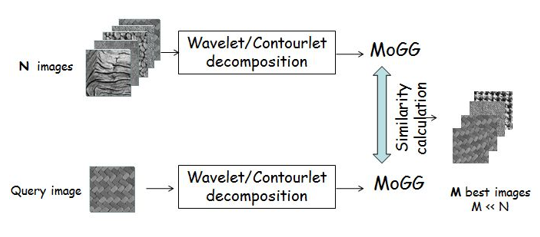
3) Texture modeling and applications
The LARIVIA laboratory previously undertook a research project focused on creating a robust statistical model using the mixture of generalized Gaussians (MoGG) formalism. This model was specifically designed for texture modeling, with a strong emphasis on applications in content-based texture retrieval and defect detection in fabric images. Utilizing the MoGG approach, the laboratory significantly advanced the capabilities of texture analysis, marking a notable achievement in the realms of computer vision and artificial intelligence.